
Our goal is to create a branch with two commits: the first adding a single README file, and the second changing this file slightly. All of this without running git.
First of all, why?
Chances are if you clicked on this post I don’t have to convince you why anyone would want to do this… ‘cause it’s fun! :) But also, it should help understand some of the main data structures in git, the “git objects”. I personally think understanding how they work and how they relate to one another is deeply valuable and allows for a better experience when using git.
What will you need?
This is a hands-on tutorial, in the sense that you should be able to copy the code snippets and make commits without git on your own machine. We will be doing everything with python (I wanted to do it in Bash, but Bash strings cannot include the null byte and that complicates things quite a bit).
NOTE: although following these steps should produce a valid git commit, it’s advisable not to use this “in production” as git commands will perform a lot of safe checks and special handling that we will skip for the sake of simplicity. If you need to create commits programmatically, check libgit2.
What is a git object, BTW?
Object are immutable units of storage in Git. They are compressed using the
DEFLATE algorithm, and referenced by the SHA-1 hash of their contents (though
there is a work in progress to support SHA-256). You can see the objects at the
.git/objects directory of any git repo; some will be inside two-hex-digits
subdirectories (these are called loose object), and some will be collective
stored in files under .git/objects/pack (these are called
packed objects). The latter is more optimized as it allows to use “deltas” to
minimize redundancies when storing similar objects.
Objects are one of the most important structures in Git; they are responsible for storing the different versions of the project files, as well as other metadata like the structure of the directories, authors and dates of each commit, etc. Here is an example containing the four most important git objects and how they interact with one another:
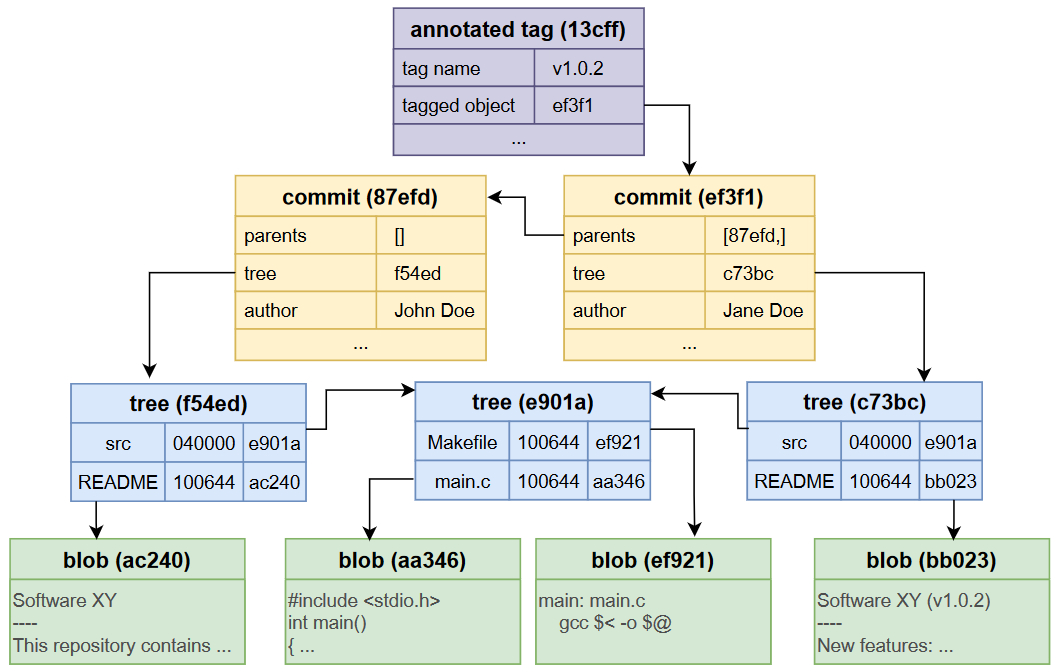
Yes, commits are not diffs, but snapshots of the whole project at a given
time (stored in an efficient manner, of course). The diffs are generated on-the-fly
when needed, such as when running git show <commit>.
Making a blob
Without further ado, let’s start writing some code. To start, we need a way to make blobs (Binary Large Objects), which are used to store file contents. A blob has the following structure:
blob {content size}{null byte}{content}
In fact, the header part is similar across different objects, so let’s create a
write_obj() auxiliary function, which will be responsible for creating and
storing a loose object in our git repo:
import hashlib, zlib, os
def write_obj(objtype, content):
'''
Writes the loose object to the git object data base and returns
its sha1 object. The content must be a byte stream.
'''
data = f"{objtype} {len(content)}\0".encode() + content
sha1 = hashlib.sha1(data)
hex_sha1 = sha1.hexdigest()
path = f".git/objects/{hex_sha1[:2]}/{hex_sha1[2:]}"
os.makedirs(os.path.dirname(path), exist_ok=True)
with open(path, "wb") as f:
f.write(zlib.compress(data))
return sha1
Writing a blob now it’s a piece of cake:
def write_blob(content):
return write_obj("blob", content.encode())
Making a tree
Next, we need a way to describe the directory structure which will contain our README file. That’s the job for a tree object, which is structured as:
tree {content size}{null byte}[list of entries]
Where each entry has the format:
{mode} {filename}{null byte}{sha1 of tree or blob in binary}
We won’t go into to much detail about the file mode, so its sufficient to say
that 100644 represents a regular file with no execution permission.
Note that, in git, all the file attributes (i.e. its name and mode) are stored
in the directory structure, not the blob. The blob only holds the file
contents. “What about subdirectories?” - you may ask. These are represented by
trees as well, whose hashes are referenced by the parent tree. Anyway, here is
our write_tree() function:
def write_tree(filenames, hashes):
mode = 100644
entries = b""
for name, hash in zip(filenames, hashes):
entries += f"{mode} {name}\0".encode() + hash
return write_obj("tree", entries)
Commit it
The last step is to create a commit to encompass our tree object. A commit in git has the following structure, where the “parents” section is optional and may contain as many parents as needed:
tree {hash}
parent hash1
parent hash2
...
author {name} <{email}> {author_date} {author_timezone}
committer {committer} <{email}> {committer_date} {committer_timezone}
{commit message}
Some important things to highlight here: the author and committer date are stored as seconds since the Epoch; the timezone is encoded as an offset from UTC; and yes, the author may be different from the committer. This happens, for example, when you cherry-pick a commit authored by another person. The new commit will have the same author, but you will be set as the committer.
OK, let’s write our function to create a commit:
import time
def write_commit(tree_sha1, parents, author, committer, msg):
content = f"tree {tree_sha1}\n"
for parent in parents:
content += f"parent {parent}\n"
content += f"author {author} {int(time.time())} {time.strftime('%z')}\n"
content += f"committer {committer} {int(time.time())} {time.strftime('%z')}\n"
content += "\n"
content += msg
return write_obj("commit", content.encode())
Branches
With all of the above set, we can write a simple function that takes one of our created commits’ hash and creates a branch on it:
def write_branch(name, hash):
with open(f".git/refs/heads/{name}", "w") as f:
f.write(hash)
If this seems confusing to you it may be because we usually think of branches as commit chains, but in reality, they are nothing more than labels. The way git retrieves the commit chain (or better yet, the graph) is by traversing the commits through their “parent” pointers, starting from the branch’s tip commit. Furthermore, if we didn’t create a branch after making our commits here, they would be considered dangling objects because they can’t be reached from any reference (branch, tag, HEAD, etc.). So git’s garbage collector would eventually prune them from the repo.
Let’s test!
Finally, let’s wrap it all together:
# First commit
author = "John Doe <john@doe>"
blob1_sha1 = write_blob("This is a simple README file\n")
tree1_sha1 = write_tree(["README"], [blob1_sha1.digest()])
commit1_sha1 = write_commit(tree1_sha1.hexdigest(), [], author, author,
"Add the README file")
# Second commit
blob2_sha1 = write_blob("This is a simple README file\nWith one extra line\n")
tree2_sha1 = write_tree(["README"], [blob2_sha1.digest()])
commit2_sha1 = write_commit(tree2_sha1.hexdigest(), [commit1_sha1.hexdigest()],
author, author, "Add another line to README")
# Create branch
write_branch("my_branch", commit2_sha1.hexdigest())
And now, let’s validate it with git:
$ git log -p my_branch
commit 28188fd39b658ff830cd063de722e3803561eef2 (my_branch)
Author: John Doe <john@doe>
Date: Thu Dec 28 08:07:23 2023 -0300
Add another line to README
diff --git a/README b/README
index a0a40df..fe62de5 100644
--- a/README
+++ b/README
@@ -1 +1,2 @@
This is a simple README file
+With one extra line
commit a33ef02efcf8616ff65faf746780971e740c31c6
Author: John Doe <john@doe>
Date: Thu Dec 28 08:07:23 2023 -0300
Add the README file
diff --git a/README b/README
new file mode 100644
index 0000000..a0a40df
--- /dev/null
+++ b/README
@@ -0,0 +1 @@
+This is a simple README file
Success! :) You can find a condensed script version of this code here: commit.py.
Further reading
- Git Book, Chapter 10.2 - Git Objects
- My “Git Under the Hood” slides
- Introduction to Git talk by Scott Chacon
- post: a tour of git’s object types by Emily Shaffer, Junio C Hamano, and others.
- pack-format docs (to understand more about packfiles and deltification).
Til next time,
Matheus